Key tools/skills:
- E-commerce Public Dataset by Alibaba as a data source
- Python (Pandas, dbt) as a data transformation tool
- Python-Kafla as a data stream processing
- Apache Airflow as a data pipeline orchestration tool
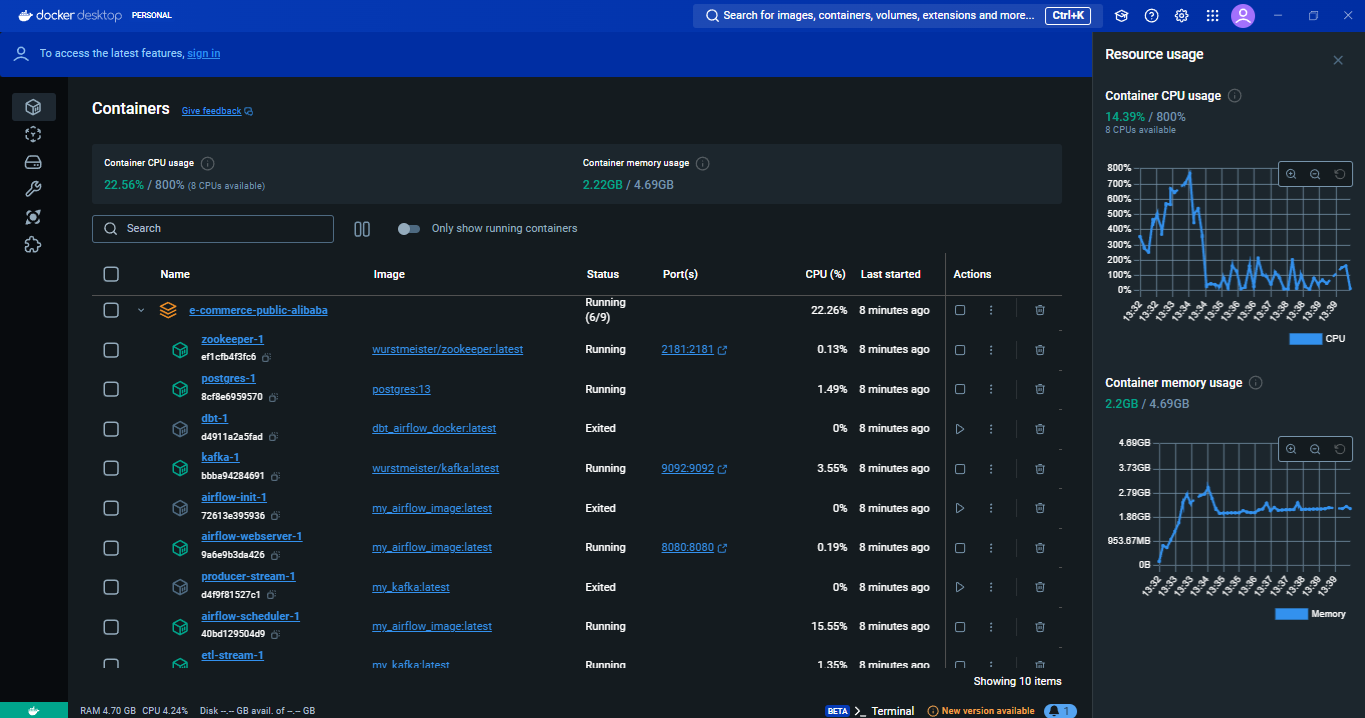
- Docker as containerization tool
- BigQuery as a data warehouse
Project : https://github.com/nairkivm/e-commerce-public-alibaba-etl
In the world of data engineering, the Lambda architecture stands out as a robust framework for processing large volumes of data. This architecture combines both batch and stream processing to handle real-time and historical data efficiently. In this blog post, we’ll explore an ETL project tailored for an Alibaba e-commerce platform, showcasing how Lambda architecture can be implemented using various tools and technologies.
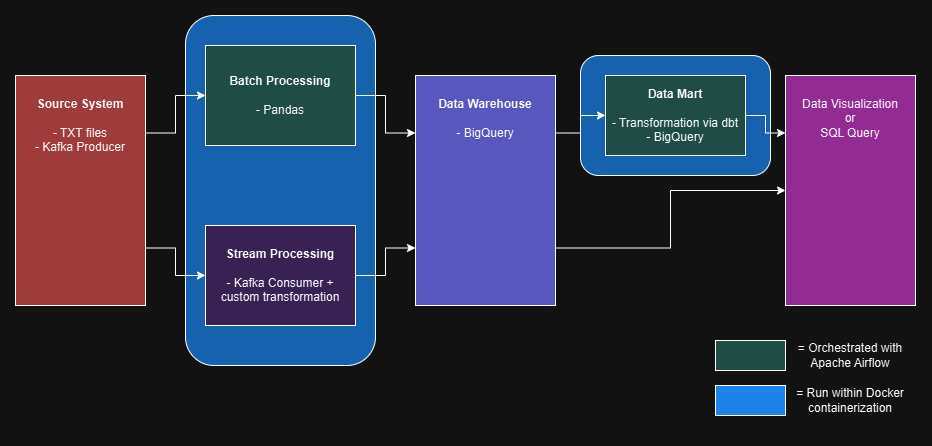
Part I: Batch Processing
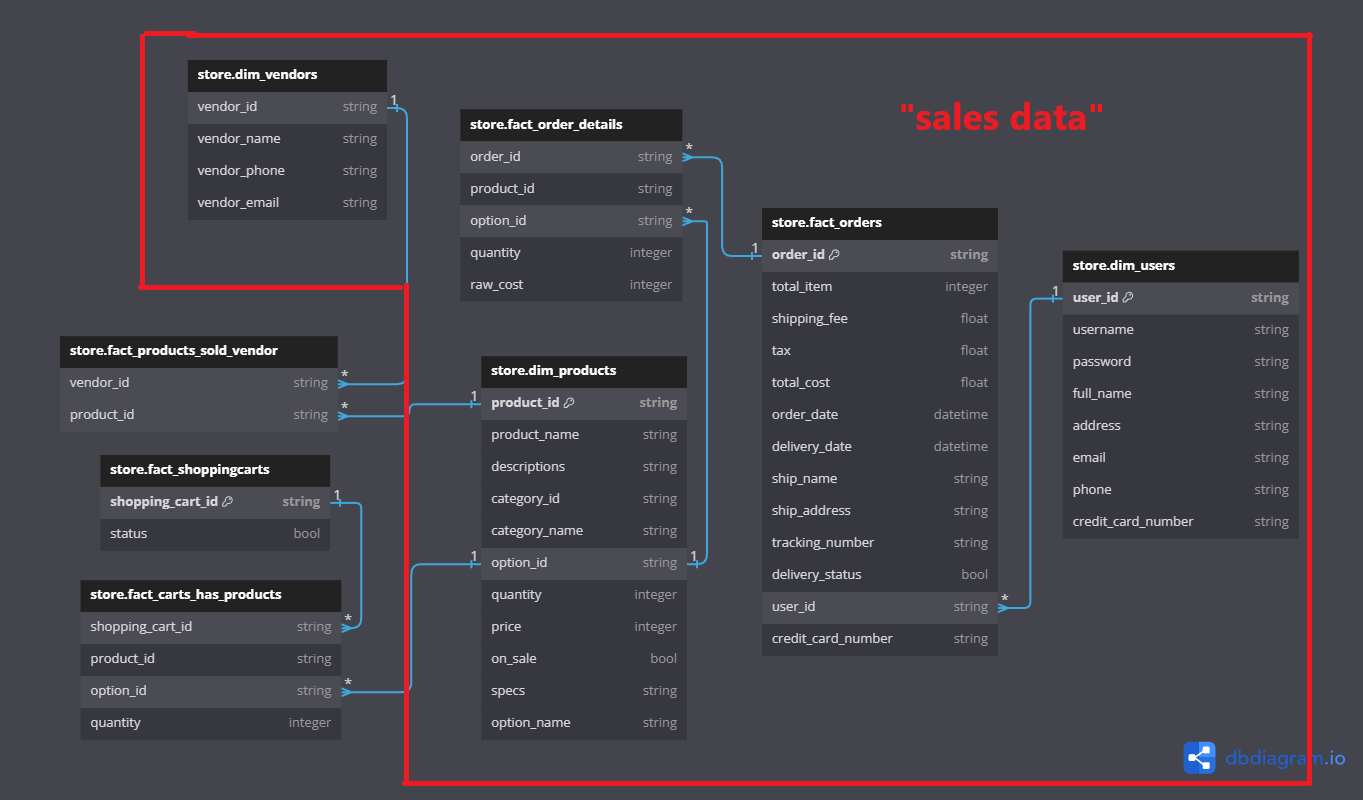
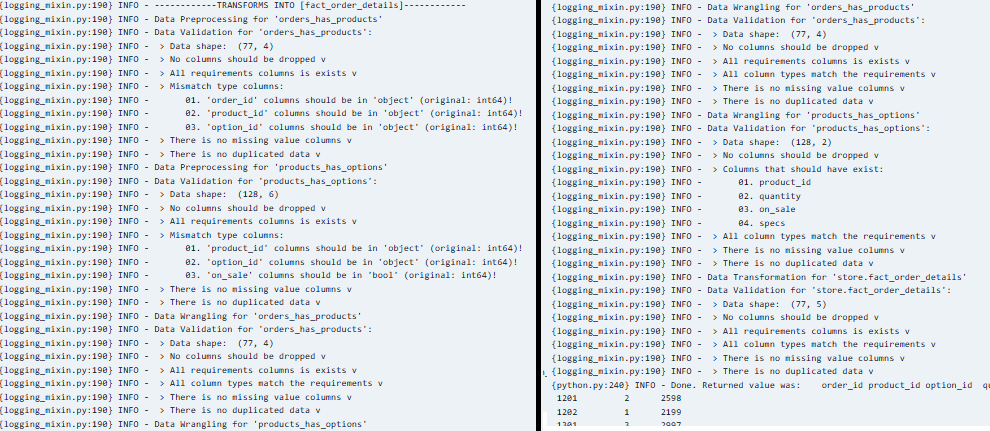
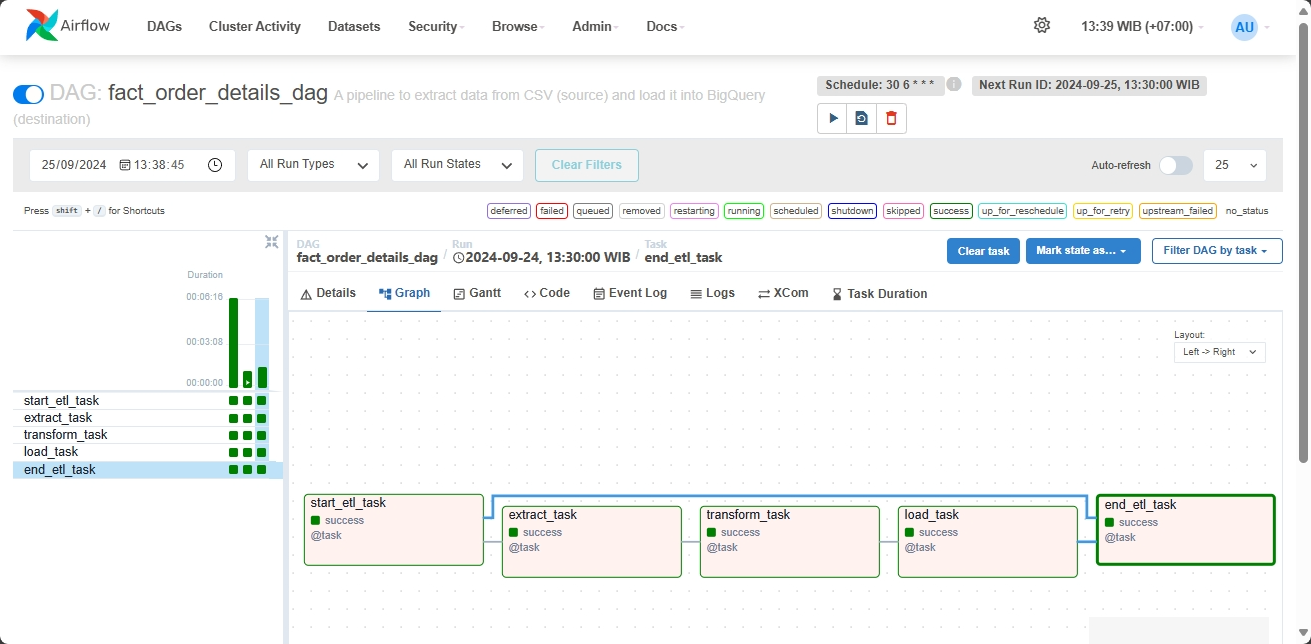
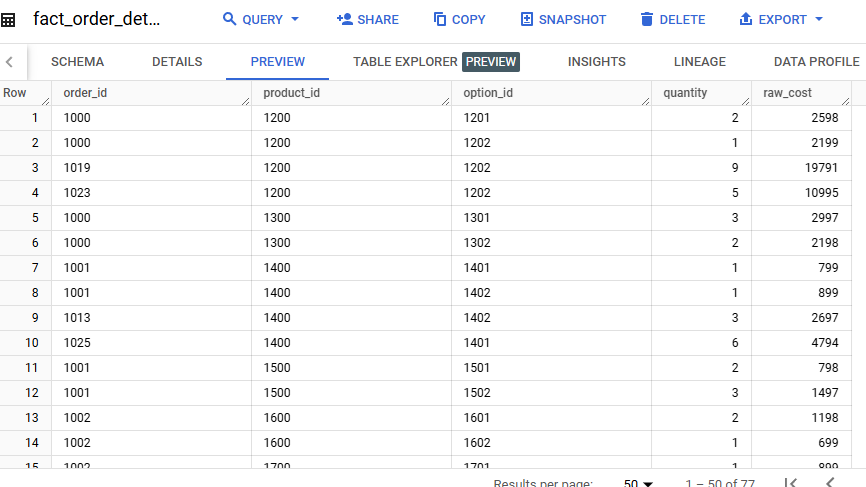
The batch processing component of this ETL project is designed to handle “sales” data. Using Pandas, we extract data from text files, transform it, and load it into Google BigQuery. This process ensures that large volumes of historical data are processed efficiently, providing a solid foundation for business analytics. For every step in this process, there is a data validation method so that the final result must meet all data requirements.
- Extraction: Data is extracted from text files containing historical sales records.
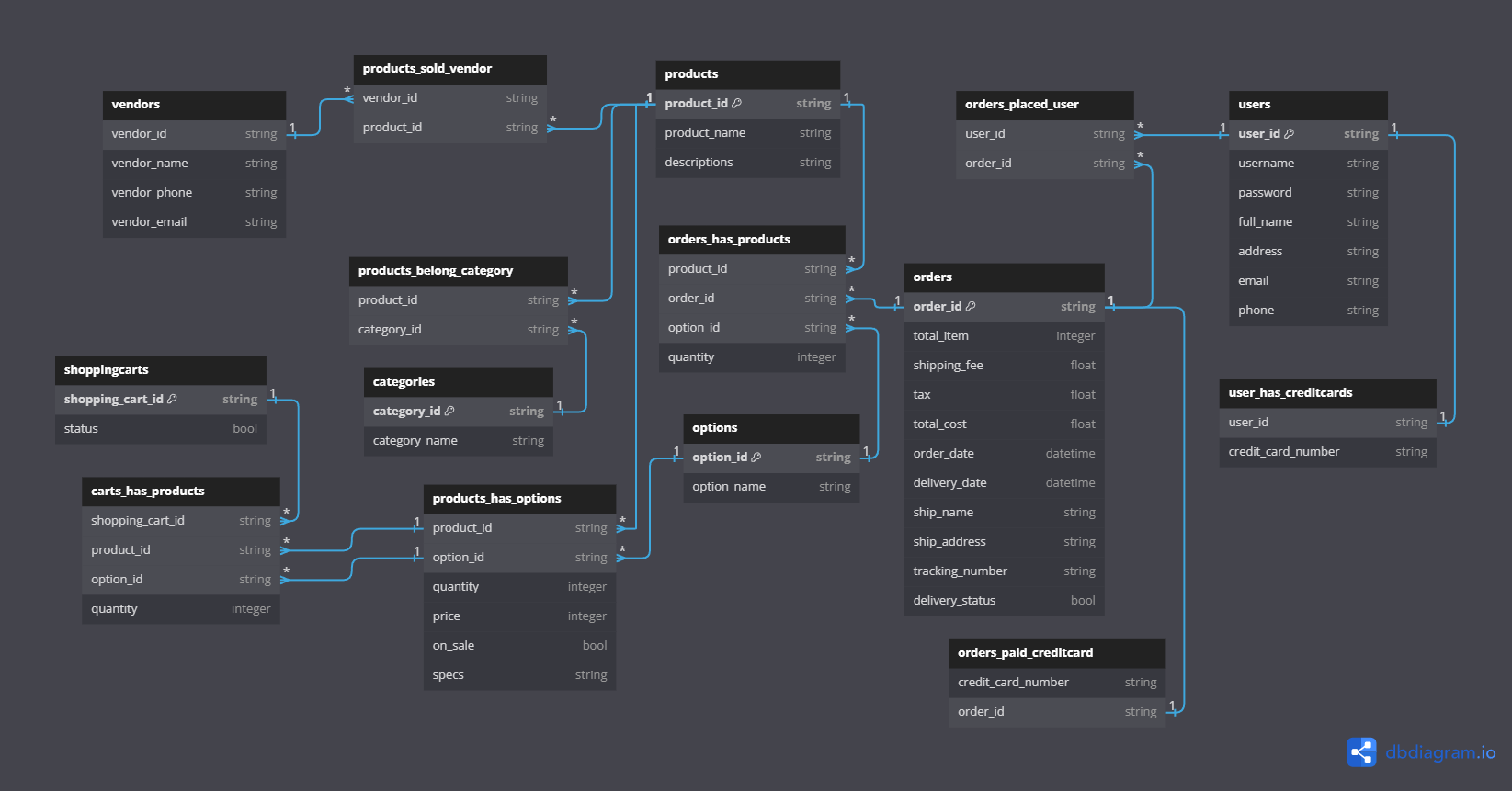
- Transformation: Using Pandas, the data is cleaned, aggregated, and transformed to meet the analytical requirements.
- Loading: The transformed data is then loaded into Google BigQuery, where it can be queried and analyzed.
Part II: Stream Processing
The stream processing component focuses on real-time data, specifically “customer cart” and “vendor availability” data. By leveraging Kafka, we can broadcast topics and process data in real-time. This allows vendors to monitor their product availability dynamically.
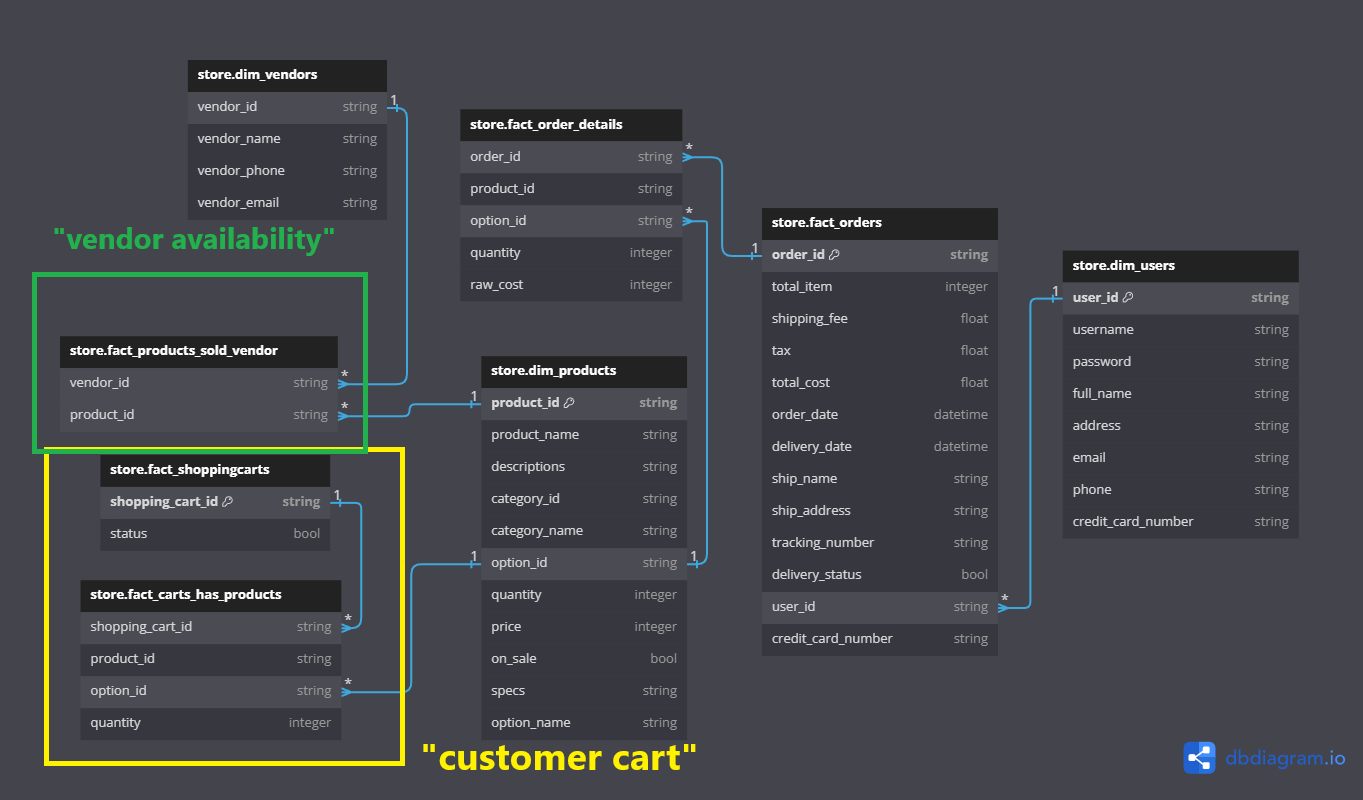
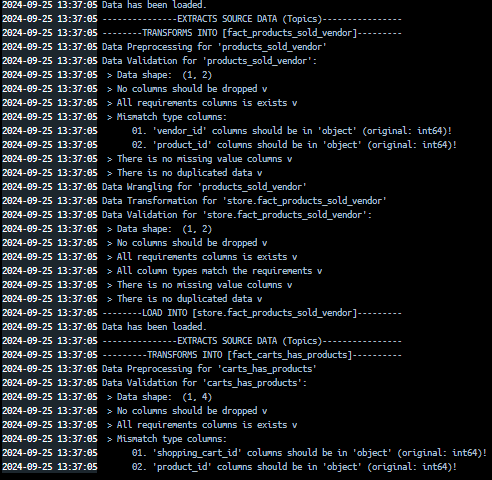
Real-time data from various sources such as customer interactions and vendor updates is simulated using Kafka Producer and then ingested using Kafka Consumer. Every single message or data is then processed with Python utilities (and Pandas) and loaded into BigQuery, ensuring that it is available for immediate analysis and action. Vendors can monitor product availability and customer behavior in real-time, enabling quick decision-making.
Part III: Integrating Lambda Architecture and dbt
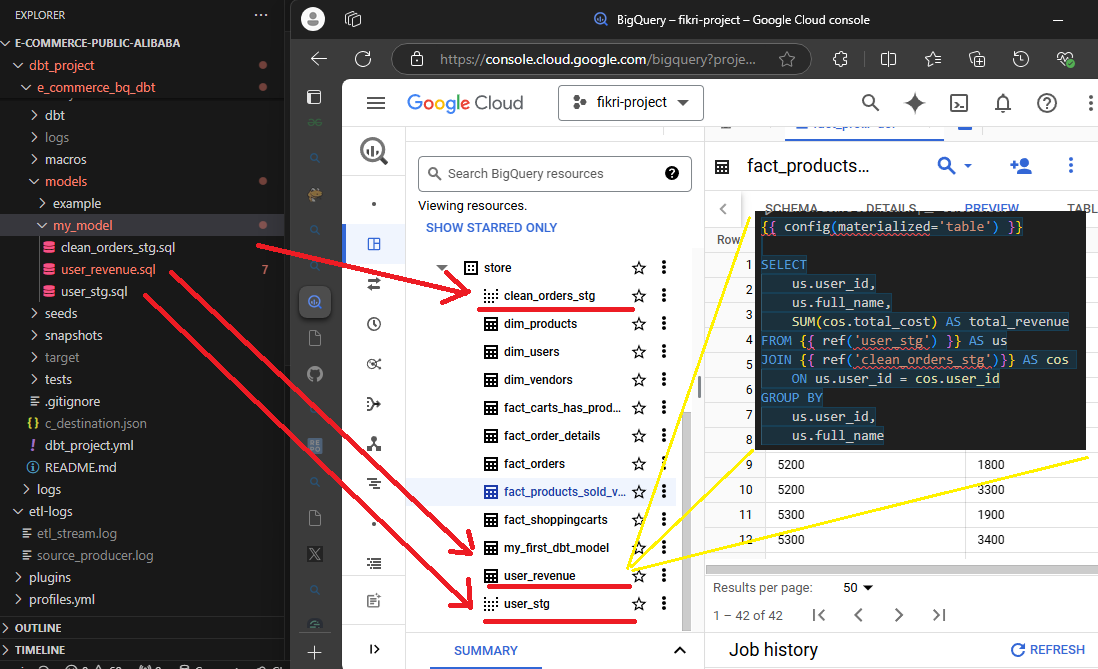
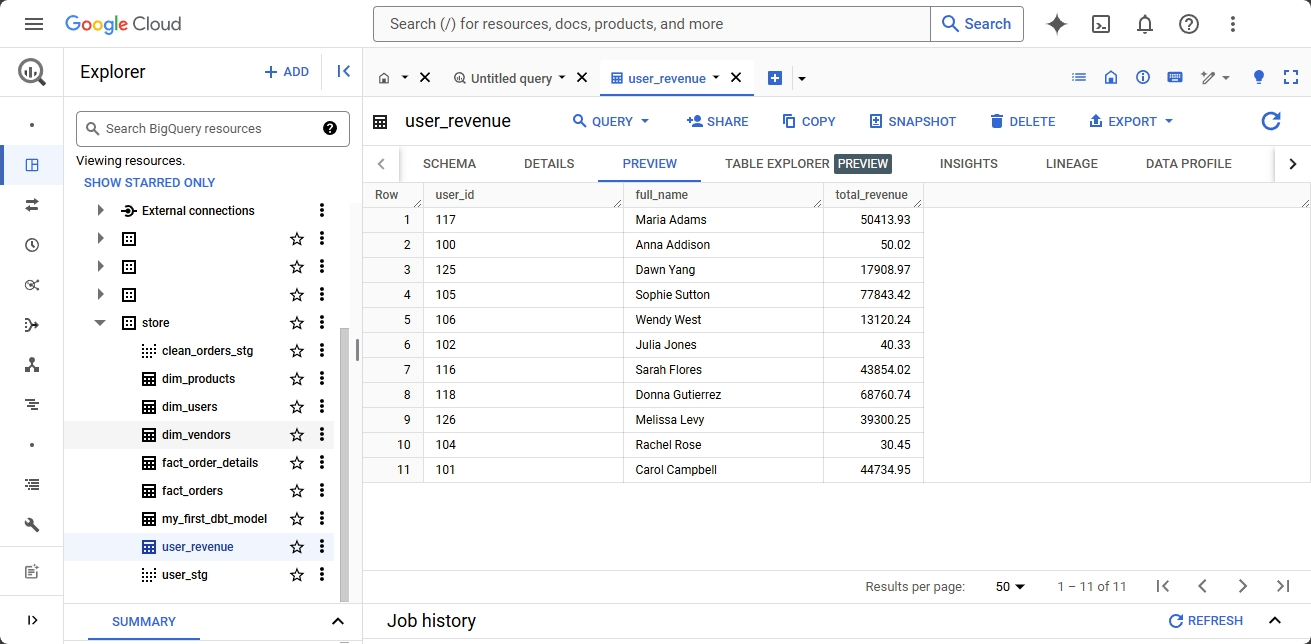
Combining batch and stream processing, this ETL project embodies the Lambda architecture. This dual approach allows us to handle both historical and real-time data seamlessly. The transformed data can be directly queried in the data warehouse platform or integrated with BI tools. This data provides actionable insights, helping businesses make informed decisions. Further transformation is achieved using dbt (data build tool), which refines the data for advanced analytics and reporting or simply serving data for the “data market”.
Conclusion
Implementing Lambda architecture in an ETL project offers a powerful way to manage both historical and real-time data. By combining batch processing with stream processing and leveraging tools like Pandas, Kafka, and dbt, we can create a robust data pipeline that meets the needs of modern data-driven businesses. This approach not only ensures efficient data processing but also provides valuable insights that drive business growth.
Posted at 2024-09-25